Meet Ops
Deploy. Scale. Govern.
The MLOps backbone for enterprise AI. Serve any model, manage GPU clusters, fine-tune LLMs, and govern everything on your infrastructure.
AI Infrastructure Is Painful
ML teams waste months on infrastructure instead of building models. IT teams struggle to govern what they can't see.
GPUs Sitting Idle
Expensive H100s and A100s are allocated but underutilised. No visibility into who's using what or why.
Months to Production
Models work in notebooks but take 6+ months to deploy. DevOps bottlenecks kill innovation.
No Governance
Shadow AI everywhere. No audit trails, no cost tracking, no idea who's calling which models.
Surprise Cloud Bills
No departmental budgets, no chargeback, no way to predict costs. Finance is not happy.
Everything to Run AI at Scale
From GPU management to model serving to governance:one platform for your entire AI operations.
GPU Management
Maximize utilisation of your expensive GPU clusters with intelligent allocation and slicing.
Model Serving
Deploy any model:from scikit-learn to GPT:with auto-scaling and high-performance inference.
LLM Fine-tuning
Fine-tune open source LLMs on your proprietary data without it ever leaving your infrastructure.
Model Registry
Version, track, and manage all your models in one place with complete lineage and governance.
LLM Management
Centralised control for all your LLM providers. Bring your keys, manage access, track usage.
Observability
Complete visibility into every model call, every GPU hour, every dollar spent.
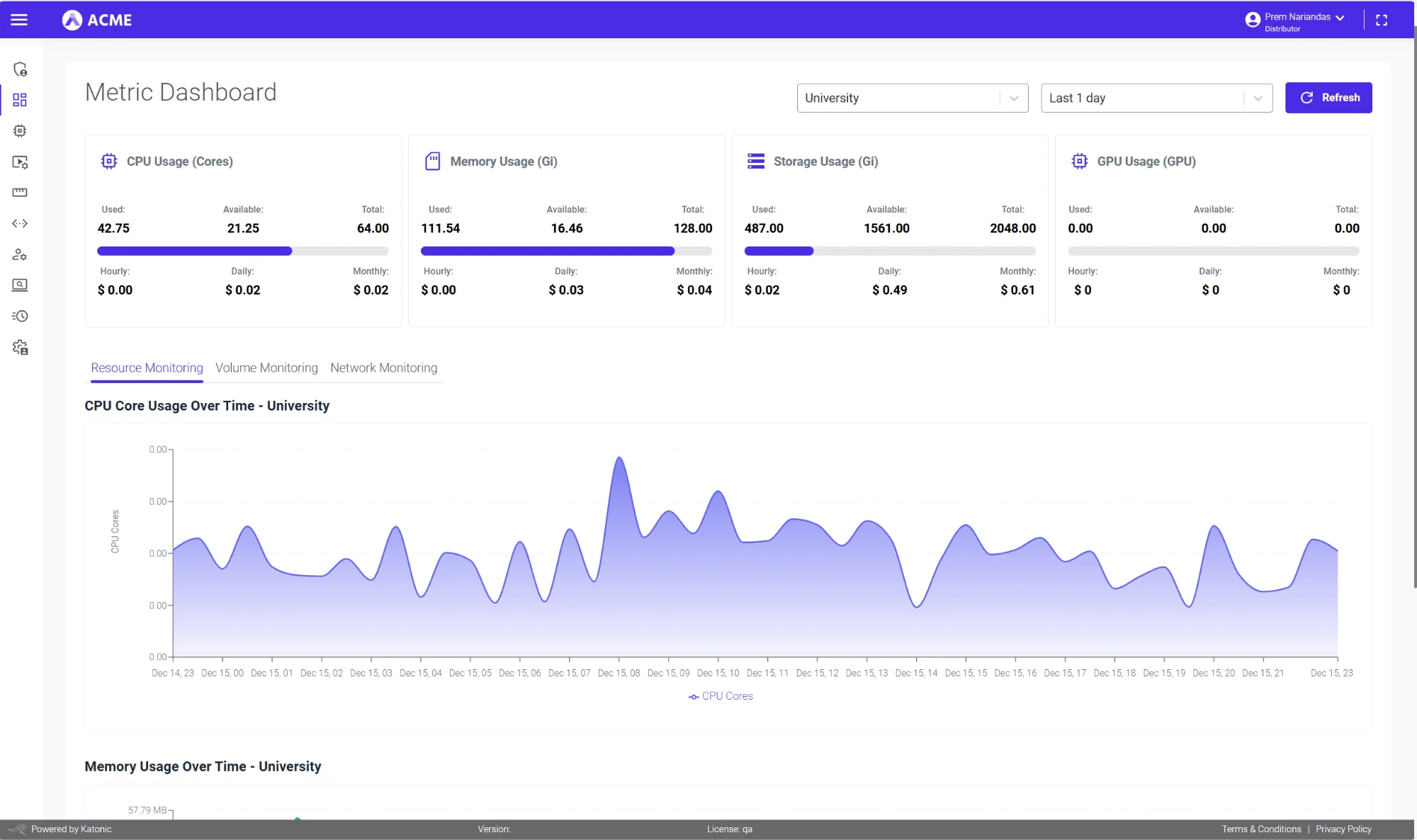
Get More from Your GPUs
Your H100s and A100s are expensive. Ops ensures every GPU hour is tracked, allocated, and optimized:with departmental quotas and real-time chargeback.
NVIDIA MIG Slicing
Slice a single A100 into multiple isolated instances for different workloads.
Departmental Quotas
Allocate GPU budgets by team. Engineering, Research, Finance: each gets their share.
Real-Time Chargeback
Track exactly who used what. Generate accurate internal billing reports automatically.
Service Templates
Pre-configured GPU environments (PyTorch + A100, TensorFlow + V100) for consistent deployments.
NVIDIA H100
80GB HBM3 • 3.35 TB/s bandwidth
NVIDIA A100
80GB HBM2e • MIG capable
NVIDIA L40S
48GB GDDR6 • Inference optimized
Self-Service Clusters. No IT Bottleneck.
Spin up Ray, Spark, or Dask clusters on-demand. Process massive datasets without waiting for infrastructure tickets.
Apache Spark
Large-scale data processing and ETL. On-demand clusters that scale with your data.
- ✅ Big data processing at scale
- ✅ Spark SQL & DataFrames
- ✅ Auto-scaling clusters
Ray
Distributed ML training and hyperparameter tuning. Scale from laptop to cluster with no code changes.
- ✅ Distributed ML training
- ✅ Hyperparameter tuning
- ✅ Reinforcement learning
Dask
Parallel Python computing. Scale pandas and NumPy workflows to clusters seamlessly.
- ✅ Pandas-like operations at scale
- ✅ Lazy evaluation
- ✅ Dynamic task scheduling
Serve Any Model. Any Framework.
From traditional ML to the latest LLMs: deploy with enterprise-grade performance and reliability.
LLM Serving
High-performance serving for large language models with continuous batching and optimized throughput.
Traditional ML
Deploy XGBoost, scikit-learn, LightGBM, CatBoost and other traditional ML models with ease.
Deep Learning
Serve PyTorch, TensorFlow, and ONNX models with TensorRT optimization for maximum performance.
RAG & Embeddings
Deploy vector databases, embedding models, and rerankers for production RAG applications.
Hugging Face
Any HF model
PyTorch
Native support
TensorFlow
SavedModel format
ONNX
Cross-platform
XGBoost
Tree models
Custom
Docker containers
From Experiment to Production. Automated.
Complete MLOps pipelines with experiment tracking, CI/CD, and zero-downtime deployments.
MLflow Integration
Track experiments, compare models, log parameters and metrics. Full MLflow integration built-in.
Hyperparameter Tuning
Automated hyperparameter optimization with Bayesian methods. Find the best model configuration automatically.
CI/CD Integration
Connect to Jenkins, GitHub Actions, GitLab CI, or Azure DevOps. Automated testing and deployment.
Blue-Green & Canary
Zero-downtime deployments with automatic rollback. Gradual rollouts with performance monitoring.
Model Comparison
Side-by-side comparison of models with performance metrics. A/B testing framework built-in.
Auto-Retraining
Trigger retraining on data drift or performance degradation. Keep models fresh automatically.
Centralised LLM Control. Your Keys. Your Rules.
One place to manage all your LLM providers. Users add their API keys, IT controls access, developers build:with complete visibility and governance.
Bring Your Own Keys
Add API keys for OpenAI, Anthropic, Google, Azure, and any LLM provider. All stored securely.
Access Control
Control which teams and users can access which models. RBAC for every LLM.
Quota & Budget Control
Set spending limits by user, team, or project. Track costs across all providers.
Usage Observability
See who's using what, how much it costs, and track every request in real-time.
Run Anywhere. Your Infrastructure.
Deploy on AWS, Azure, GCP, on-premises, or air-gapped environments. Your data never leaves your control.
Public Cloud
AWS, Azure, GCP with your VPC
On-Premises
Your data centre, your rules
Air-Gapped
Zero external connectivity
Multi-Cloud
Span multiple providers
One-Click AI Infrastructure
Deploy pre-configured tool stacks with enterprise security in seconds, not days.
n8n
Workflow orchestration with enterprise security
Langfuse
LLM observability and tracing
CrewAI
Multi-agent coordination
MLflow
Experiment tracking & registry
Airflow
Data pipeline orchestration
Prefect
Modern workflow automation
Built for Enterprise Scale
Everything ML and IT teams need to run AI in production:securely and efficiently.
RBAC & SSO
Role-based access control with SAML, OIDC, and LDAP integration.
Zero Trust Architecture
Never trust, always verify. Security at every layer of the platform.
Audit Trails
Complete logs of every model call, every deployment, every change.
Cost Management
Departmental budgets, chargeback reports, and spending alerts.
Monitoring & Alerts
Prometheus, Grafana, and OpenTelemetry for complete observability.
Compliance
ISO 27001, SOC 2, HIPAA, GDPR-ready with data residency controls.
Explore the Platform
Ops is part of the Sovereign AI Platform. Discover related products.
Ready to Run AI at Scale?
See how Ops can maximise your GPU utilisation, accelerate model deployment, and govern AI across your enterprise.